[ad_1]
Disclaimer: Every hour, we learn something new about AI and the capabilities of large-scale models. This piece reflects our thinking as of December 5, 2023 and may be subject to Bayesian updating.
Change happens slowly, and then all at once — especially in complex industries like healthcare. Just five years ago, venture capital investments in healthcare AI were emerging and exploratory. Half a decade and one global pandemic later, we’re living in a brave and more ambitious new world defined by an unbridled enthusiasm for leveraging revolutionary technologies like AI. Pointing this technology at previously intractable problems in key industries such as healthcare, life sciences, and beyond is among the greatest opportunities of the century.
2022 was the year the broader public bore witness to material advancements in AI research that have matured from lab to life. ChatGPT educated over 100 million people globally about transformers in just two months. What was once a nascent area of research has now become technology’s next platform shift, and with that, investors ask — how will generational AI companies be built in healthcare, life sciences, and beyond?
AI-first companies are in the business of advancing AI as a science, whereas AI-enabled companies are implementation and distribution machines. The two company phenotypes establish moats at different layers — AI-first companies innovate just above hardware, whereas AI-enabled companies create enterprise value at the application-level.
We can no longer afford to conflate AI-first and AI-enabled companies.
For founders, knowing what kind of company you are building is essential for recruiting proper talent, partnering with aligned investors, securing sufficient capital, and deploying a viable business model. AI-first companies require deep AI research acumen, investors willing to take a long view, materially more capital, and potentially less conventional business models than AI-enabled peers.
In reality, this distinction is a spectrum, not a binary.
In reality, this distinction is a spectrum, not a binary.
Impactful companies will be built with both approaches, and far more will be AI-enabled than AI-first. For AI-first companies, though, we believe the fruit will be worth the labor. Influence over the technology stack from the ground up enables tight control over cost structure, immeasurable product optionality, and greater defensibly relative to AI-enabled companies that defer the exercise of scientific inquiry to those that are AI-first.
So far, the largest AI-first companies have been new entrants building for horizontal applications (e.g., OpenAI, Anthropic, Perplexity), countered by big tech product launches (e.g., Google’s Bard, Amazon’s Q). Yet to be realized, vertical and industry-specific platforms, such as those in healthcare and life sciences, will showcase the expansive capabilities of large-scale models to deliver real-world impact.
For founders, we believe enduring AI-first companies — in healthcare, life sciences, and beyond — will follow these six imperatives.

The six imperatives for AI-first companies
1. Create and sustain an undeniable data advantage
AI-first companies exhibit an insatiable appetite for data and employ creative means for sustainable acquisition. However, more data is not always better, as researchers have observed diminishing returns in the context of AI scaling laws. Therefore, long-term differentiation in model performance requires multi-faceted approaches to data synthesis and curation, as well as optimized model architectures.
The data strategy must align with the model purpose.
For AI-first companies, the data strategy must align with the model purpose. The data required to support a generalist foundation model designed to be proficient in many tasks will differ from that powering smaller, task-specific models. The healthcare and life sciences industries may generate 30% of the world’s data; however, the data exhaust of healthcare delivery alone is likely insufficient for developing highly performant systems. Intentional experimentation in data generation, coupled with elegant product design that facilitates model training with every user interaction, can bolster the quality of data for model training.
AI-first companies consider five key criteria to assess data defensibility:
- Scalability: is it possible to amass an asset substantial enough for large-scale model training?
- Continuity: can the dataset can be re-sampled over time?
- Propriety: how easily can the data be accessed?
- Fit: is the data relevant and suitable for a given model or task?
- Diversity: does the data adequately reflect future real-world scenarios?

Below are key data sources for AI-first companies:
Publicly Available Data: Publicly available data is self-explanatory: datasets that are freely accessible and open for public use. This type of data is ideal for initial model training and benchmarking due to its wide accessibility and sometimes, diversity. Publicly available data provides a rich source of information for a broad range of applications. However, this data often demonstrates a high potential for bias and lacking task-specificity. Additionally, because these datasets are widely used and may have been included in the training set for large-scale foundation models, risk of contamination and overfitting are noteworthy, which can result in poor performance in real-world applications or on zero or few-shot tasks. One example is MedQA, an open-source data of multiple choice questions collected from professional medical board exams. Though MedQA has been utilized as a benchmark for the performance of biomedical AI models, extrapolation of high performance on MedQA tasks into real-world settings has not been well-characterized to-date.
OpenEvidence is an AI-first company that powers physician-grade clinical decision support leveraging large-scale models to parse full-text biomedical sources for immediate answers to questions about drug dosing, side effects, curbside consults, treatment plans, and more. The platform enables efficient querying of publicly available biomedical literature via a natural language interface.
Customer-Generated Data: Customer-generated data is generated by clients of AI models during their normal course of business. This data is highly relevant to user needs and reflects real-world use cases, making it invaluable for training AI models in a dynamic and context-specific manner. Customer-generated data can also provide continuity, allowing for the development of up-to-date and responsive AI models. Nevertheless, customer-generated data can lack diversity as it can be biased towards certain customers (e.g., training on medical records from a community hospital in a rural vs. urban area), and might raise privacy concerns if de-identification techniques prove insufficient. Integral to the success of training on customer data is sampling from a sufficiently large and diversified set of customers in the curation process.
Artisight, an AI-first company developing a suite of smart hospital products, utilizes de-identified derivatives of audio and video footage from hospital customers to train small and large models across computer vision and documentation-based tasks, addressing clinical workforce shortages and burnout.
Designer Data: Designer data sets are specifically created for model training use cases through intentional experimentation and are not typically found in publicly available or customer-generated datasets. These datasets are machine-readable and scalable and are designed to be highly specific and relevant, thus filling gaps in the aforementioned data sources. Designer data sets are particularly valuable for niche applications where standard datasets may fall short or where real-world settings do not generate data via a particular mechanism or in a specific form factor. Despite these benefits, creating designer data can be both expensive and time-consuming. If deployed in isolation, these datasets may lack generalizability.
Subtle Medical, an AI-first company focused on imaging acceleration, generated millions of imperfect MRI images captured in 15 minutes, which were later utilized to train deep learning models that could reconstruct and de-noise medical imaging exams taken in shorter periods of time. In practice, imperfect MRI images provide little clinical value; however, for Subtle, these images trained deep neural networks that created a data moat for the company’s technology.
Synthetic Data: Synthetic data is a subtype of designer data that is generated through simulations or statistical models that sample from other data sources, which can be highly useful in settings where real data is sparse or sensitive. Synthetic data also reduces privacy concerns. Challenges with synthetic data stem from concerns that it may not accurately capture the complexity of real-world data. Ensuring the accuracy and relevance of synthetic data is often a complex task, which can limit its effectiveness in training AI models.
Unlearn.ai, an AI-first company focused on clinical trial acceleration, builds “digital twins,” or synthetic clinical records that are capable of reflecting accurate, comprehensive forecasts of a patient’s health over time under relevant scenarios.
Annotated Data: Annotated data sets are enriched with specific metadata or labels, providing additional context and detail. This enhancement of data quality and specificity makes annotated data particularly suited for supervised learning tasks, where detailed and accurate labels are crucial. However, the process of data annotation can be time-consuming and costly, and also carries the risk of human error in labeling, which can impact model performance negatively. In medicine, a field characterized as both an art and a science, “ground truth” labels often inject subjectivity, especially for “clinical diagnoses,” where objective biomarkers do not yet exist. Promising research has also demonstrated the ability of AI systems to perform expert labeling tasks to mitigate these challenges.
PathAI and Paige.ai, AI-first companies focused on pathology, leveraged human pathologists to annotate histopathology slides via a robust network of experts.
“Feedback as Data”: Feedback as data, which refers to reinforcement learning with human feedback (RLHF), involves using human-user feedback as a direct input for training AI models. This approach allows models to adapt to complex and nuanced real-world scenarios and align more closely with human preferences and judgments. Many AI-first companies create user interfaces that enable model training via RLHF within the application as a byproduct of usage, agnostic to the underlying infrastructure. However, this method is subject to human biases and is limited in terms of scalability. The quality and effectiveness of the AI models are heavily dependent on the quality of the feedback provided, which can be variable and challenging to standardize. Model-based reinforcement learning, where models provide feedback to other models, is a flourishing area of contemporary research and may offer more scalable systems for fine-tuning.
Abridge, an AI-first company that provides ambient documentation tools for clinicians, leverages clinician feedback on AI-authored notes to enhance note accuracy and quality across specialties.
Different data sets can and should serve distinct roles. Training data, used to teach the model fundamental patterns by providing a broad and varied base of information, will differ from fine-tuning data, which is more specialized, aimed at refining the model’s performance in specific areas or tasks and addressing any deficiencies or biases the initial training may have overlooked. Evaluation data, separate from the training and fine-tuning sets, is crucial for testing the model’s ability to generalize to new, unseen situations.
AI-first companies must balance data quality and quantity to optimize model performance. Multi-modal approaches that capitalize on the relative strengths and weaknesses of various data sources are likely to yield more enduring benefits than monolithic strategies alone.
| Data Type | Description | Strengths | Weaknesses | Example |
| Publicly Available | Datasets that are freely accessible and open for public use. | Widely accessible, diverse in nature, good for initial model training and benchmarking. | May contain biases, not always specific or detailed for particular needs, risk of overfitting. | NIH Clinical Trials database |
| Customer-generated | Data created by customers during interaction with a product or service. | Highly relevant to user needs, reflects real-world use cases, and delivers continuous data generation. | May lack diversity, potential privacy concerns, bias towards certain user groups. | Artisight |
| Designer | Custom-created datasets, tailored for specific AI tasks and not readily available in public. | Highly specific and relevant, can be created to fill gaps in existing data. | Expensive and time-consuming to create, may lack generalizability. | Subtle |
| Synthetic | Artificial data generated through simulations or statistical models, mimicking real data. | Useful in situations where real data is sparse or sensitive, no privacy concerns. | May not capture the complexity of real data, challenging to ensure accuracy and relevance. | Unlearn.ai |
| Annotation | Datasets enriched with specific metadata or labels, providing additional context. | Enhanced data quality and specificity, ideal for supervised learning tasks. | Time-consuming and costly to annotate, potential for human error in labeling. | PathAI, Paige.ai |
| Feedback as Data | Data derived from human feedback, used in reinforcement learning models. | Allows models to adapt to complex, real-world scenarios, and human preferences. | Subject to human bias, limited scalability, dependent on quality of feedback. | Abridge |
2. Recruit and empower AI scientists
AI-first companies require “multilingual” teams — meaning they employ scientists deeply skilled in AI research as well as individuals with industry and business expertise. The design of the team must reflect advancement of AI as a key business activity. In healthcare and life sciences, this might take the form of clinicians and scientists partnering with AI researchers to design models with context-aware representations for a given domain. “Interpreters” are essential for the success of multilingual teams — these are the rare individuals who boast interdisciplinary domain expertise, such as physician-informaticists, who can align various functional areas using shared rhetoric. For these reasons, AI-first companies are also more likely to benefit from an academic or industry laboratory affiliation. Atropos Health, a company focused on real world data generation for medicine, initially spun out of a Stanford AI Lab helmed by Dr. Nigam Shah.
The organizational structure must also reflect an AI-first company’s prioritization of AI from the most senior levels. The R&D organization at an AI-first company will likely operate under a different reporting structure and leadership profile compared to an AI-enabled company. AI-first companies are more likely to have a Chief Scientific Officer (CSO) with deep AI research experience, with AI researchers and software engineering resources reporting into the CSO. AI-enabled companies are more likely to have Chief Technology Officers with classical software engineering training. Below is a sample organizational chart of how an AI-first company might structure their R&D team. For AI-first companies, we highlight the parallelization of a traditional software engineering org focused on application development and an AI research org focused on methods development and model fine-tuning.
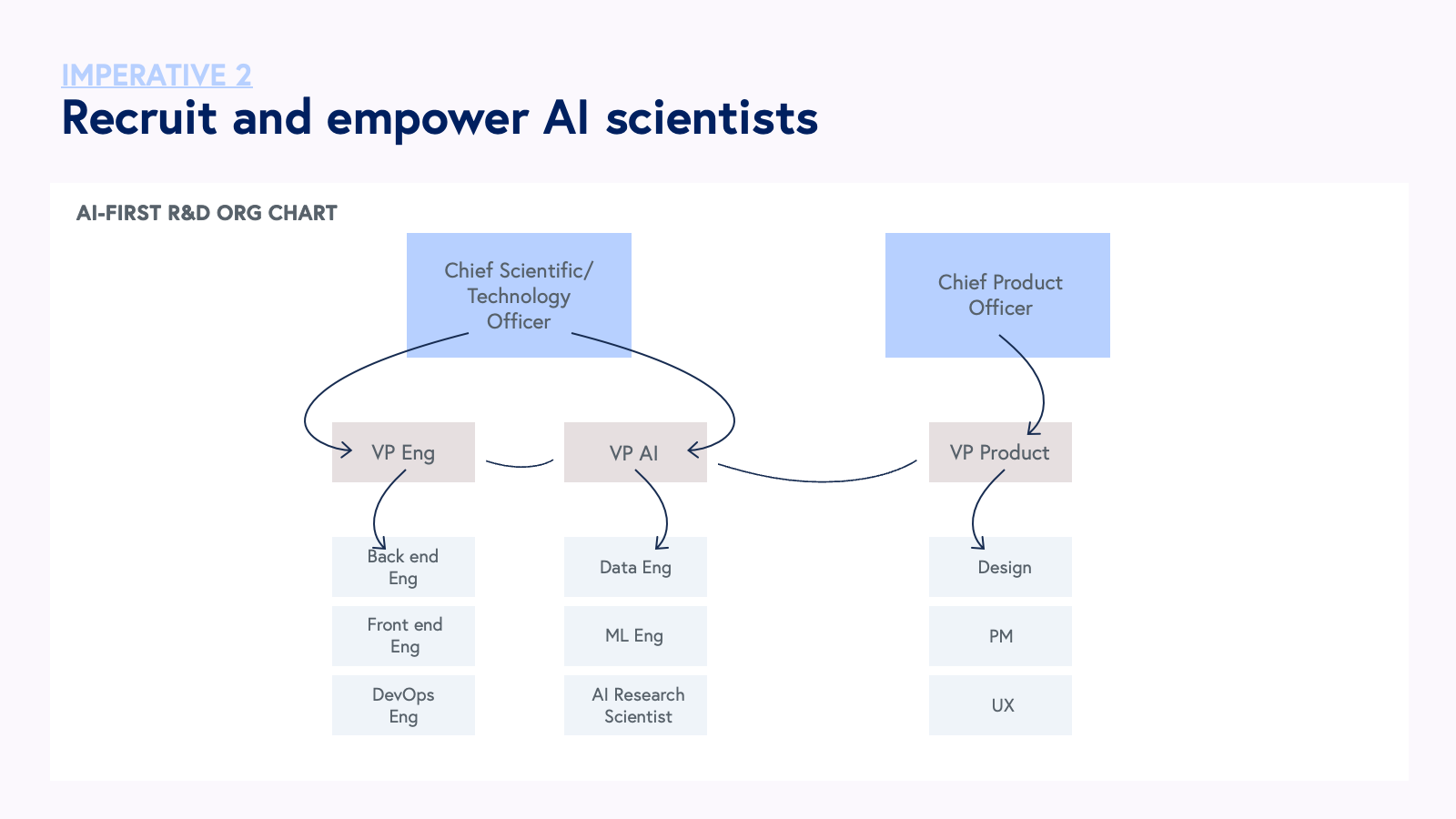
The marketing function at AI-first companies also serves AI research as a key business activity. AI-first companies publish work regularly via accessible formats such as peer-reviewed journals (e.g., Nature Machine Intelligence or New England Journal of Medicine AI) or presentations at leading AI conferences (e.g., NeurIPS and ICML). These activities are critical for demonstrating advancements in state of the art (SOTA) and contributing broadly to advancements in the field of AI.
3. Support a flexible AI stack
AI is advancing at an exponential pace as model sizes scale non-linearly and facilitate new and emergent behaviors that extend far beyond generation. By the time this blog post goes live, parts of it will be out of date. Critical for survival, AI-first companies must refrain from making rigid, irreversible, or monolithic decisions about the AI stack. Moreover, efforts to develop models that perform above SOTA benchmarks for every aspect of the stack is likely intractable for a single team. Instead, AI-first companies build modular AI stacks that leverage publicly available models (open-source, e.g. models shared on the Hugging Face Hub, and/or closed-source, e.g. GPT-4 or Claude 2.1) where others boast best-in-class performance, focusing internal proprietary model development resources in layers of the stack where the team has clear advantages due to undeniable data moats, methodological intellectual property, or other contributions of company or affiliated laboratory research.
We underscore the growing importance of open-source models across industries, but especially in healthcare and life sciences, where after many years of closed-system architectures, transparency is emerging as a core value for technological innovation. Open-source approaches grant full control over all aspects of a model and its training data, including forward-looking updates.
AI-enabled companies are more likely to rely on incumbent infrastructure, such as GPT, for a majority of AI-related product features. These companies may perform fine-tuning on top of these models, but as a result, are more likely to hit a ceiling in terms of product capabilities. By innovating lower in the AI stack, AI-first companies enjoy greater product and feature optionality over time.
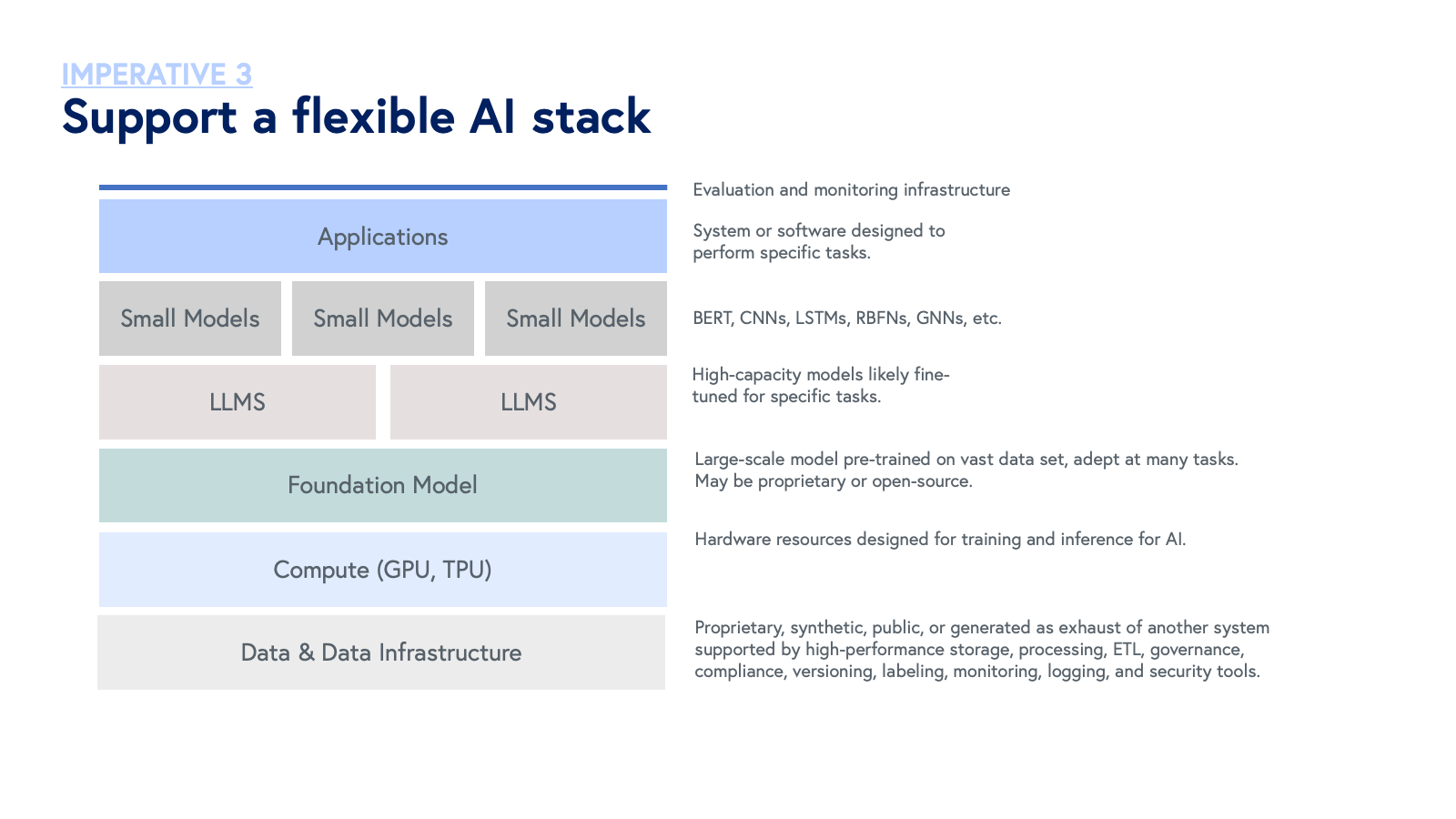
Furthermore, not all AI-first companies are building foundation models. Instead, many focus on developing smaller specialized models, which are characterized by fewer parameters. These models have been shown to challenge scaling laws for large-scale models by 1) outperforming large models on particular tasks, and 2) demonstrating superior performance when deployed in combination with larger models. By supporting a flexible stack, AI-first companies can enjoy the strengths of large models in orchestrating utilization of small models — managing, coordinating, or directing fleets of small models to address particular tasks — akin to an “AI project manager.” From a business perspective, small models offer other benefits such as reduced costs, lower latency, and greater controllability.
4. Establish distribution moats
Without distribution, the impact of a best-in-class AI model may start and end with a published paper.
Both AI-first and AI-enabled companies should seek to obtain distribution moats or advantages early on, such that it’s conceivable the product will be able to integrate with or displace incumbent technology providers over the near-term. Unlike AI-first companies, however, distribution is often the only moat for AI-enabled companies. AI-first companies enjoy both technical and distribution moats, both of which contribute to enterprise value creation.
Though direct sales can be a critical part of go-to-market (GTM), accelerating update of AI-first products in the enterprise often requires more creative strategies:
1. Product-led growth: leveraging the product for user acquisition and retention.
OpenEvidence, a biomedical AI company, partnered with Elsevier, a leading medical publisher, to launch ClinicalKey AI, a clinical decision support tool that will deploy Elsevier’s trusted, evidence-based medical information via a natural language interface.
2. Partnerships: collaborations between organizations for mutual benefits such as preferred vendor relationships.
Abridge, an AI-first company focused on tools for the clinical workforce, partnered with Epic, the leading electronic health record provider, as a preferred vendor partner for ambient documentation solutions.
3. White-labeling: rebranding and selling AI-first technology within a partner company’s product or service.
Iterative Health, an AI-first precision gastroenterology pioneering novel biomarkers for gastrointestinal disease, secured an exclusive partnership with Provation, the leading gastroenterology electronic medical record, to facilitate broad distribution in the specialty.

Distribution advantages are key, but so is the answer to the question: who pays? Payment models remain an outstanding question for AI-first companies, especially in the biomedical realm. Many emerging companies are leveraging conventional business models such as software-as-a-service and transaction-based revenue models, yet healthcare stakeholders cite cost as the top barrier to AI implementation. The healthcare industry does not have adequate resources or aligned incentive structures to subsidize a transition to AI. By some estimates, hospitals only spend $36 billion annually on all IT investments spanning software, hardware, and human resources. Payment reform will be critical.
In the interim, we expect commercial success for AI companies that deliver on Law 5 of Bessemer’s 10 Laws of Healthcare: demonstrating financial and clinical ROI. Despite our excitement for emerging methods that allow for improved diagnostics, we fear these applications will be slow to garner adoption unless the improvement in clinical outcomes drives a corresponding financial benefit, as would be the case in a value-based organization, but potentially less so in a traditional fee-for-service provider.
5. Center safety and ethics in model development
As AI permeates all aspects of public and private life, AI-first and AI-enabled companies must grapple with preserving the foundational rights of human users. Investment in AI safety and ethics is non-negotiable for AI-first companies innovating at the foundational layer. These companies must exercise caution and intention in data custodianship and a relentless commitment to model maintenance. Strategies such as continuous performance monitoring, fail-safes and overrides for human intervention, recurring re-validation against real world data, and user training that outlines key limitations of AI are employed exhaustively by AI-first companies.
In conjunction with the Coalition for Health AI (CHAI), we recognize that safety and ethics begins at the earliest stages of model development design all the way through monitoring and real world application.
At the heart of CHAI’s mission is the development of comprehensive guidelines and guardrails for healthcare AI technologies. With a principle-based approach, CHAI is spearheading efforts to harmonize existing standards and, in collaboration with the healthcare AI community and validation labs anointed by the Biden Administration’s Executive Order, establish common principles that will serve as the bedrock for creating and implementing trustworthy AI practices.
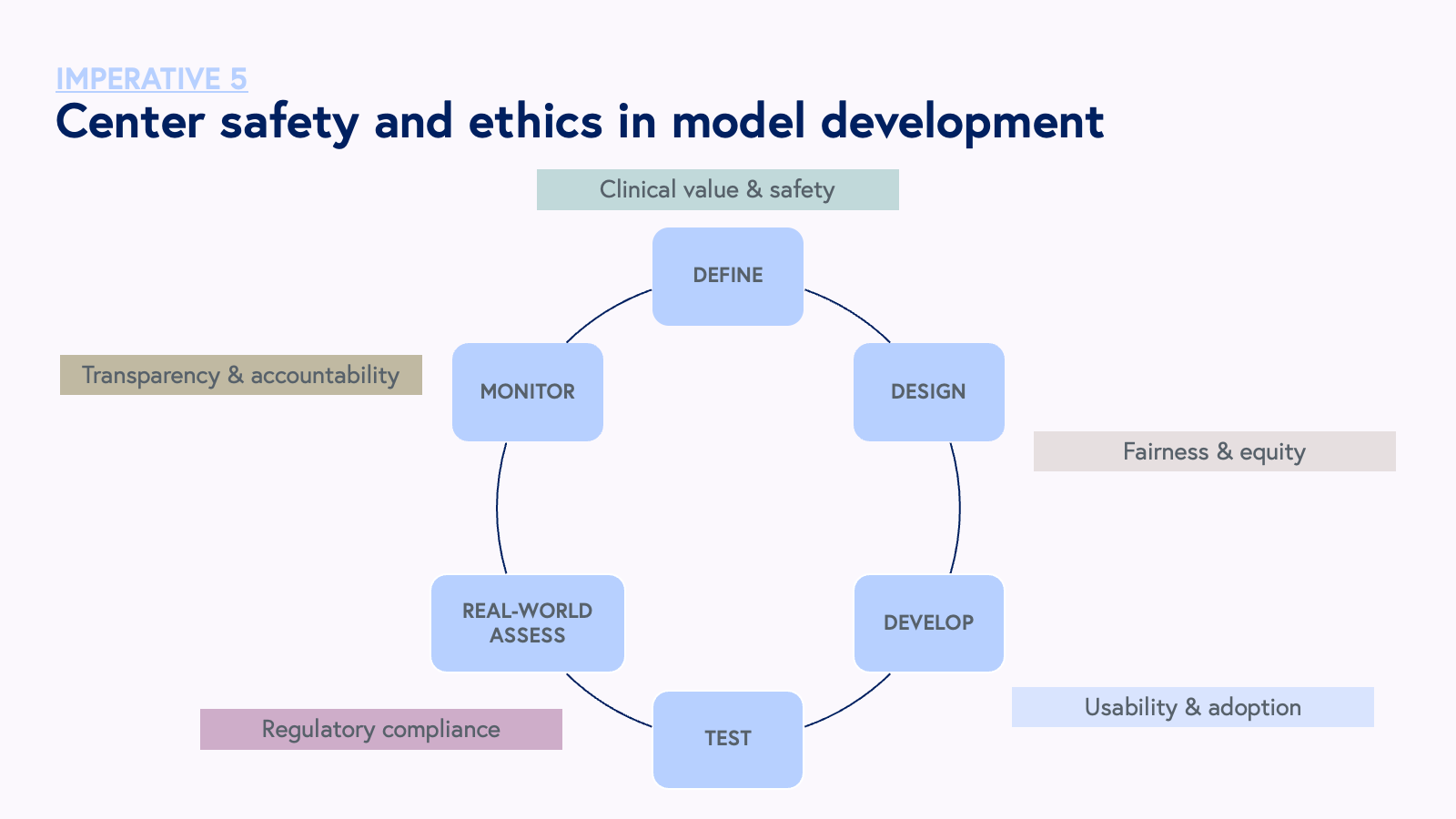
These values include:
- Safety: AI systems must not put human life, health, property, or the environment at risk.
- Accountability and transparency: Individuals involved in the development, deployment, and maintenance of AI systems must maintain auditability, minimize harm, report negative impacts, and communicate design tradeoffs.
- Fairness with bias management: AI systems should manage bias effectively to ensure disparate performance or outcomes for selected groups are minimized.
- Security and resilience: AI systems should be able to withstand adverse events or changes and maintain their functions and structure.
- Privacy enhancement: AI systems should adhere to norms and practices that safeguard human autonomy, identity, and dignity, in compliance with relevant privacy laws and standards.
6. Earn trust by solving real problems
While AI-first companies are built on data, they thrive on trust. Trust is earned when stakeholders perceive that their problems are met with curiosity and empathy rather than techno-solutionism. It is earned through reliability, accuracy, and respect for the human condition and a focus on value creation for society.
While AI-first companies are built on data, they thrive on trust.
AI is one of many technologies we have for solving societal problems. There is a difference between what AI is capable of and where AI creates value.
Whether it makes sense to leverage AI is specific to the problem, task, and industry. AI is both a means to an end – many patients do not care whether a drug was discovered by AI or by human scientific intuition, they care that there is an accessible therapy with a favorable side effect profile that may treat their condition – and also a tool for solutioning – re-designing clinician user experience leveraging ambient data capture to address administrative burden and burnout.
As with any emerging technology, we must earn the right to use it, and we ought to demonstrate superiority with the way things have been done before. AI-first companies have a tall-order – they must innovate technologically and demonstrate an ability to solve real-world problems, all while operating in alignment with the value systems that govern society.
Setting the record straight
Building AI-first companies, especially in healthcare and life sciences, is not an easy feat. However, the impact of AI-first companies will be greater, financial returns superior, and moats more enduring than their AI-enabled counterparts. Though we’re in the earliest days of witnessing AI-first companies in the wild, including industry-specific opportunities in healthcare and life sciences, the stark contrast in the approach, capabilities, and leadership of AI-first companies clearly distinguishes them from traditional software or AI-enabled businesses. AI research will continue to be the lifeblood of generational opportunities in AI. It is imperative that the venture capital and startup ecosystems commit to distinguishing AI-first companies from AI-enabled and become students of how these companies are built and scaled. As we continue to interrogate the role of AI as an agent for problem-solving, we implore founders to think deeply about what kind of AI company they seek to build and what that will mean for the path ahead. Perhaps most importantly, let us not mistake a clear view for a short distance. This is just the beginning.
If you’re a founder, researcher, clinician, or scientist building at the intersection of AI and healthcare space, we want to hear from you. We also welcome feedback and additional perspectives on our thinking. Email morgan@bvp.com and steve@bvp.com, and let’s continue this conversation on Twitter @morgancheatham @stephenkraus!
[ad_2]
Source link